This post will continue to be modified for at least a month from the publish date. I just didn’t want to wait another month before publishing, so people can start to get some use out of it early. If you have resources, comments, anything you think that could be useful to others, please add a comment and if it makes sense, I may add it to the post. This will also be used as a resource for the attendees to the CHC.JS MV* Battle Royale meet-up.
Recently I’ve undertaken the task of reviewing some JavaScript MV* frameworks to help organise/structure the client side code within an application I’m currently working on. This is about the third time I’ve done this. Each time has been for a different type of application with completely different requirements, frameworks and libraries to consider.
Unlike Angular and Ember, Backbone is a small library. Marionette adds quite a lot of extra functionality and provides some nice abstractions on top . All mentioned frameworks/libraries are free and open source.
I found a useful tool for helping with the selection process about a year ago. It’s called TodoMVC and it contains a generous collection of applications all satisfying the requirements of a single specification (a small web app that allows the person using it to add todo notes etc.). So basically they all do the same thing, but use a different JavaScript framework or library to do it. It’s still being maintained. Addy Osmani’s blog post on the project is here.
The idea is that you can work through a decent size selection of applications that all do the same thing.
This assists the R&D developer or architect to make informed decisions on which JavaScript framework or library will suite their purposes, if any.
There are also a couple of Todo apps (vanillajs and jquery) that don’t use a framework at all.
There’s a template to use as a starting point, so you can create your own.
Just bear in mind though, that the TodoMVC app doesn’t really show case what Ember and Angular has to offer.
On Addy’s post There are a collection of good points on how to create your selection criterion under the heading “Our Suggested Criteria For Selecting A Framework”.
I’ve heard a few times that “all you really need to do in order to make an informed decision on which framework or library to go with is just write a small app for each of the frameworks, do a bit of reading and maybe watch a few screen casts. Shouldn’t take more than a day”. I disagree with this. I don’t think there is any way you can learn all or most of the pros and cons of each framework in a day or even two. Depending on how much time you have, my recommended approach would be to go through the following activities in the following order (give or take). Spending as little or as much time as you have, ideally in a few iterations, for each of the offerings you’re investigating.
- Listen to a pod-cast (say, on your way to/from a clients or even in your sleep. Good time savers.)
- Read some of the documentation
- Watch a screen-cast on each one
- Play with some examples
- Evaluate on features you (definitely or may) want verses features available. Features need to be learned. If you don’t need them, you will probably be better going with the offering that doesn’t have the features you don’t need, but has the architecture to add them (thinking Backbone) if/when you do need them.
- Are the features implemented in an architecture that you believe is good (I.E. are the layers muddied)?
- Read some blog posts, tutorials.
- Read some opinions and evaluate for yourself.
- Start testing it’s limits
- Decide whether you like its opinions imposed
- Does it impose enough or to many opinions for you and your team
As the JavaScript MV* landscape is constantly and very quickly changing, the outcome of your evaluation will have a short use by date.
This is my attempt to distil the attributes of the discussed offerings. I’ve attempted to come at this with an open mind. Hopefully this will help save some work for those that come after me. lists are sorted in the order of most useful to me. I make no apologies for the abundance of links, as I’ve also used this for a resource collection point and hope that this post will fall into the category of a “one stop shop” for what I consider to “currently” be the top three contenders in the client side MV* line-up. In saying that though, there are other strong contenders like Meteor not discussed here, as it’s more than just a client side MV* framework. Without further ado, here they are…

AngularJS
Intro
Opinionated framework that has Models, Views and Controllers, but does not conform to the MVC pattern.
Core Team
Igor Minár, Miško Hevery, Vojta Jína.
All work at google.
Backed by the commercial giant Google (you decide whether that’s a good thing).
Community
- IRC: #angularjs
- AngularJS on Google+
Conferences
Statistics
- Version: 1.2.5
- Payload Size: Depends on handlebars development version 85kb
- development version 716.7kb
- minified 99.8kb
- minified and compressed < 36kb
- Age: Initial Github commits: January 2010
Performance
See Backbone Performance below.
Documentation
Pod-casts
Screen-casts
Blog Posts, Tutorials, etc.
Features
- Directives: used via Non HTML compliant tags, attributes, comment and class names. Although there are options to make it compliant: via the class (not recommended) and data attributes.
- scope. The first half of this video shows how the scope may be confusing to those new to Angular. If I can not tell how code will work without running it, it violates the Principle of Least Astonishment (PoLA). It seems quite clunky to me.
Positive
- Good for long running and complex applications with deep nested view hierarchies
- Two-way data binding
- All tests run against IE8 (good for those that are locked into legacy MS)
- Test driven (and more vocal about it than Ember)
- Payload is about 1/3 smaller than Ember
Negative
- Steep learning curve compared to Backbone, but not as steep as Ember.
- Dirty checking to keep views and models in sync is costly. Ember keeps sync in a more elegant way. Possible perceived downside to this is Ember models have to inherit from DS.Model (next point addresses this as a positive though). Also discussed here under the “Performance issues” heading.
- Models are Plain Old JavaScript Objects (POJO’s). Doesn’t have to be anything special. Now there’s an argument here that attempts to explain this as being a selling point of Angular, but in reality what happens is a violation of the Uniform Access Principle, thus creating tight coupling. How’s that? Well now the view needs to know too much about the model’s members. Discussed in more detail here. For example if one of the models properties is a function, the view has to know this. So you see this sort of thing in the view {{area()}} (so we’re pulling our JavaScript into our view.) where as with Ember because it’s models are well defined and you can use computed properties on them, all the view needs to specify is an identifier, then you’ll see this sort of thing in the view {{area}}. The Ember model then creates a computed property with the same name. The opposing view is that in ES5 you can just hide your functions etc. behind property getters and setters. Most developers take the path of least resistance, so I think most will be doing it the wrong way.
Interesting Plug-ins
- ?
Useful Tools
- “AngularJS Batarang” for Chrome browser (it’s an extension)

EmberJS
Intro
Opinionated framework that has Models, Views and Controllers, but does not conform to the MVC pattern.
Core Team
Yehuda Katz, formerly of Rails and SproutCore projects.
Tom Dale, Peter Wagenet, Trek Glowacki, Erik Bryn, Kris Selden, Stefan Penner, Leah Silber, Alex Matchneer.
Backed by the JavaScript community.
Community
- IRC: #emberjs
- EmberJS Community
- Ember Weekly (news email)
Conferences
Statistics
- Version: 1.2.0
- Payload Size:
- development version 1.1MB
- production version 1.0MB
- minified and GZipped 67kb
- Age: Initial Github commits: April 2011
Performance
See Backbone Performance below.
Documentation
Pod-casts
- JavaScript Jabber Ember Tools
- JavaScript Jabber Ember.js (also covers some backbone)
- JavaScript Jabber Ember.js & Discourse
- EmberWatch
Screen-casts
Blog Posts, Tutorials, etc.
Features
- the ember-application class gets added to the root element (body) in the ember JavaScript file. I was wondering how this class was magically added to the markup. Couldn’t find any documentation on it, so had to look through the JavaScript.
Positive
- Good for long running and complex applications with deep nested view hierarchies
- Aggregates model data changes and update the DOM late in the RunLoop.
- Well defined models and computed properties (See Angular negative point around this).
- Test driven
Negative
- Steepest learning curve out of the three. Why? Because there’s more in it. If you need it, great! Maybe you don’t. If not, is the extra learning worth using it? Part of the “more in it” may also be around the elegant way things have been designed, I.E. more constraints to push the users down the right path, thus higher chance of less friction and pain in the future of your application, that is of course if your application does things they way Ember says they must be done. I’m seeing some of these things in the likes of the well defined models and computed properties.
- Payload is the largest out of all three.
Interesting Plug-ins
- ?
Useful Tools
- “Ember Inspector” for Chrome browser (it’s an extension)
- ember-tools. Listen to and/or read the pod-cast linked to above. Provides file organisation, scaffolding, template pre-compilation, generators, CommonJS (that’s node.js style) modules. and other goodies. Useful for setting up your project to conform to the Ember conventions, so you don’t end up fighting them.
Angular versus Ember views
Pod-casts
Screen-casts
Blog Posts, Tutorials, etc.
- Evil Trout Ember versus Angular (possible bias toward Ember)
- Why AngularJS beat EmberJS
My Thoughts
Both Frameworks Appear to be Targeting a Similar Problem Space
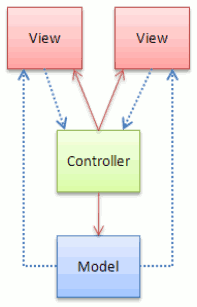
Don’t believe everything you read. Test it before you buy it. I’ve come across quite a few articles that are just incorrect. Even by reputable people. Sometimes because the frameworks have changed how they do things and/or their documentation has changed. So don’t just take it all at face value. The concept of MVC has changed over the past decade. Although concepts have changed, a pattern doesn’t change, that’s why it’s a pattern. Something everybody familiar with a pattern understands. If an implementation starts to change, then it no longer conforms to the pattern and should not be named after the pattern, as this just brings confusion. Microsoft’s ASP.NET MVC framework is a perfect example of this. It does not follow the MVC pattern (documented in 1979) and so should never have been named MVC. Ask me in the comments to explain if your not aware of how this is. In the MVC pattern Models are not injected into views by Controllers. With the MVC pattern, Views listen to events from a Model (The View is actually oblivious to the Model) which the Controller has hooked up, since the Controller knows about both the View and the Model. This may not be your understanding of MVC? More than likely this is due to certain frameworks being labelled as MVC when they are not, thus bringing the confusion. The following image provided by Gang-Of-Four depicts the MVC pattern.
Angular Doesn’t Pretend JavaScript has Real Classes
Personally I find both frameworks have opinions that make me nauseous.
Like Angular’s scope and Embers class-hierarchy abstraction. Yes Harmony will have pseudo classes for the classical programmers that struggle with JavaScripts declarative prototypal inheritance. (disclaimer: my roots are in classical OO languages) The way I feel about it: Say a whole lot of JavaScript programmers start using a classical OO language and decide they don’t like the way it does classical inheritance, so the classical object oriented language authorities decide to add syntactic sugar on top of the language to make it’s classical inheritance “look” more like prototypal inheritance for those that struggle with the classical paradigm. Now seriously, why would you muddy the language to cater for those that are not prepared to spend the time learning how it works?
Another and probably the most obvious reason why JavaScript didn’t have classes, is so that object hierarchies could be built up via composition (only inheriting what is actually needed) rather than having to inherit every member needlessly from a base class (essentially knowing far more than is actually needed). Once you have to re-factor your way out of a code base that has abused inheritance thus creating very tightly coupled code by violating one of the object-oriented design principles (information hiding), the perils of over using inheritance will become very clear.
I’m open to exploring what the other client side JavaScript frameworks and libraries have to offer and I’d love to hear from everyone that’s had experience with them.
Angular and Ember do a Lot For You
With all the bells and whistles, both frameworks impose strong opinions that you must follow in order to make the magic (in a lot of the cases convention) work. Once you’ve learnt Angular and/or Ember, productivity is maximised. But… you must be building your application the way the framework creators want you to. At this stage, I’m not supper comfortable with that. This is where Backbone and friends comes in to its own.


BackboneJS + MarionetteJS
Intro
Backbone is an unopinionated library that has Models, Views but no Controllers out of the box. That’s right, a library rather than a framework because your code needs to know about it, rather than it knowing about and executing your code. It does not follow the MVC, MVP or MVVM patterns. It’s views and routers act similarly to a controller. Marionette brings the controller to Backbone (if you want or need it), thus you can keep your router doing what it should be doing (just routing, with no controller logic).
What I find strange is that a Backbone view contains a model. I’m not sure I’d even call this a MV* library, as it may introduce confusion.
Backbone’s sweet spot is providing the user with brief and casual interaction. Doesn’t provide help or guidance with deallocating memory and detaching events. Assumptions are that the user isn’t going to be using this application all day without closing the browser window. Although in saying that, there are many applications that use Backbone for this type of thing, but they must provide explicit code to release event handlers. Marionette provided some help here for older versions of Backbone. and Backbone has improved things with newer versions. You will still need to keep in mind that event handlers need to be released though (Backbone’s view.remove takes care of this now). Marionette provides abstractions to deal with these like the close method which provides a place to add clean-up code and then calls Backbone’s remove. Failing to remove event handlers are the largest cause of memory leaks in Backbone.
Core Team
Backbone: Jeremy Ashkenas
Marionette: Derick Bailey
Community
IRC: #marionette on FreeNode. Little activity.
Conferences
Statistics
- Version: 1.1.0
- Payload size: Depends on Underscore development version 43kb or minified and gzipped 4.9kb
- Backbone development version 59kb
- Backbone minified and gzipped 6.4kb
- Age: Backbone: Initial Github commits: September 2010
Performance
The second half of this video shows the difference between Backbone and Ember performance. What I’ve seen to date, is that in terms of performance, Backbone leads, second is Ember, third is Angular. You need to decide how much performance matters to your situation and whether or not it’s “good enough” for the framework/library you choose.
Documentation
Pod-casts
- Marionette.js
- JavaScript Jabber Ember.js (also covers some backbone)
- Backbone.js
Screen-casts
- How to build modular Backbone applications using MarionetteJS
- Tuts+ Intro to Marionette
- Plugging in MarionetteJS. This resource is about adding Marionette to a MongoDB document explorer. Also features source code.
- Github
- BackboneConf 2013 Talks
Blog Posts, Tutorials, etc.
Books
Features
- ?
Positive
- Free to use any templating engine. You can use underscore as it’s the only dependency of backbone, or any other of your choosing.
- A lot of excellent documentation
- Very flexible in how you may want to use it
- Minimalist library
- Easy to learn (not a lot of it).
- Payload including dependencies is the smallest out of all three. About 9 times smaller than Ember.
Negative
- No two way data-binding. Although if you want/need it, you could use the likes of the data binding offerings below in the Interesting Plug-ins section.
- No provision for handling nested views. This is where the likes of Marionette’s Backbone.BabySitter comes in
- More work required to build large scale applications than the likes of Angular or Ember (just a library after all).
- If your large complex application is written in Backbone, chances are you have added a lot of boiler plate code. Any new developers coming onto the project will have to get up to speed on this code. If your large complex application uses Angular or Ember and the new developers coming onto the project have worked with these frameworks, they more than likely won’t have to learn the boiler plate code that they would have to with the likes of Backbone, because it’s part of the framework.
Interesting Plug-ins
- There is a similar offering: backbone.layoutmanager which I haven’t really looked into, but according to Derick Bailey (Marionette BDFL) is more of a framework where as Marionette is a library.
- Two way data binding with Rivets.js, Knockback.js, backbone.stickit
NYTimes backbone.stickit “is a Backbone data binding plug-in that binds Model attributes to View elements with a myriad of options for fine-tuning a rich application experience”. What looks to be nice about this is that unlike most model binding plug-ins I’ve seen, it doesn’t require you to add any extra tags like Angular to your view. In fact your views are not contaminated at all. - Backbone.routefilter plug-in allows you to add behaviour that will be executed immediately before and/or after a route (Backbone.Router or Marionette.AppRouter) executes.
Useful Tools
- “Backbone Debugger” for Chrome browser (it’s an extension)
- Frameworks that leverage backbone and provide more functionality
Now a few more concepts that I think are important to know about if your serious about using a client side JavaScript MV* framework/library and in regards to module loading, this applies to the server side also.
Templating
Blog Posts etc.
- net tuts+ Best Practices When Working With JavaScript Templates
- net tuts+ An Introduction to Handlebars
Some Offerings
- handlebars.js
- mustache.js templates are compatible with handlebars. handlebars just has more functionality
- underscore.js
I covered some of the template engines here under “Templating Engines evaluated”, or just use the likes of the Template Engine Chooser
Coupling Domain with Framework
As Boris Smus has said and I think it’s right on the money (although I disagree with his comments around JavaScript class as per my comments above):
Once you bite the bullet and decide to invest in a framework, you often have no easy way to move your code out of it.
If you pick Backbone, but decide mid-cycle that it’s not for you, you are in for a world of hurt:
If you have core functionality that you want to release, release it in pure JavaScript, not as a jQuery plug-in, or some MV* module.
Because there are so many JavaScript frameworks coming and going, and we don’t want to invest to heavily into any one of them,
we really need to keep our investment separate from the library/framework code.
To avoid library/framework and class-system lock-in, a good approach in regards to JavaScript MV* libraries/frameworks,
Is to keep the core functionality separate from the user interface code, thus giving us two separate layers.
This gives us flexibility to swap user interfaces as they come and go, yet still keep the majority of our code in an API layer.
The API layer being a logical single layer, but can be modularised, and loaded as needed, AMD style.
With this separation, we can implement the two layers in the following manner.
1) Build the base layer using pure JavaScript prototypal inheritance.
This is the part you write with the intention of keeping and possibly using parts for other projects also.
This base layer will implement an API that you will want to spend a bit of time getting right.
This is the code that will make the most use of unit tests.
To get the separation clear in your head, think of the user interface code as a client that uses this API as if it was service API sitting on the server.
This way you can avoid creating leaky abstractions.
2) Use an MV* library/framework to implement the user interface, and call into the base layer directly.
This lets you move quickly and focus entirely on writing the user interface.
This architecture should facilitate building your user interface on a solid foundation and avoid investing heavily into an offering that you may want to swap out further down the track.
Modules
In most browsers, just including a script tag will cause the rest of the page to stop rendering until the script has loaded then executed.
Which is why if loading scripts synchronously, they should be concatenated, minified, compressed and included at the bottom.
Loading scripts asynchronously don’t block, which is why you can load multiple scripts in parallel where ever you want (any more than 2-3 concurrently and performance will degrade). Make sure to concatenate your scripts though.
What we see as our projects get larger, is that scripts start to have many dependencies in a way that may overlap and nest.
The simplest way to load asynchronously is to create a script tag and inject it into an existing DOM element on your page.
Because the DOM element already exists, the rendering is not blocked.
See the first code example here
// Create a new script element.
var script = document.createElement('script');
// Find an existing script element on the page (usually the one this code is in).
var firstScript = document.getElementsByTagName('script')[0];
// Set the location of the script.
script.src = "http://example.com/myscript.min.js";
// Inject with insertBefore to avoid appendChild errors.
firstScript.parentNode.insertBefore( script, firstScript );
If you want or need to get serious about script loading (which you’re probably going to have to do at some stage), use a best-of-breed script loader. This will also push you down the path of defining modular JavaScirpt (AKA modules).
Next we look at employing script loaders to load our modules…
Formats available for Writing and Using Modular JavaScript
Asynchronous Module Definition (AMD)
For writing modular JavaScript in the browser. To save re-writing what’s already been done… http://addyosmani.com/writing-modular-js/ see “AMD” section, explains it well. What does AMD actually give us? http://requirejs.org/docs/whyamd.html#amd Separation of Concerns, essentially placing value on interface rather than implementation. Mapping of module IDs to different paths. Lots more. Allows asynchronous loading of modules and their dependencies, which is something we need on the client side, but is not generally a requirement for the server side. For getting started, see “Getting Started With Modules” under the AMD section here. Also check out the AMD specification and of course the most common AMD implementation: RequireJS. Then at some stage you’re probably going to want to concatenate and minify your modules and that’s where the likes of r.js comes in. r.js also has a node.js adapter which allows you to use node’s implementation of require.
Tom Dale (core team member on Ember) also has some interesting ideas around why he thinks AMD is not the answer.
CommonJS API (Optimised for the server)
Although we have the likes of browserify a CommonJS module implementation that can run in the browser or browser-build… makes CommonJS modules available in the browser and is very fast. Ryan Florence discusses module loaders in the pod-cast listed above “JavaScript Jabber Ember Tools” where he decided to move to CommonJS rather than RequireJS for his Ember Tools mostly due to speed. So it’s horses for courses. Decide what your requirements are, then decide which module loader satisfies the most of them. Also see “writing modular js” under the “CommonJS” section.
Providing a rich standard library. The intention is that an application developer will be able to write an application using the CommonJS APIs and then run that application across different JavaScript interpreters and host environments. With CommonJS-compliant systems, you can use JavaScript to write:
- Server-side JavaScript applications
- Command line tools
- Desktop GUI-based applications
- Hybrid applications (Titanium, Adobe AIR)
Why it doesn’t excel in the browser “out of the box”: http://requirejs.org/docs/whyamd.html#commonjs
ES Harmony (Modules implemented in the language. were not quite there yet, but the current offerings look to be a pretty good step in the right direction).
http://addyosmani.com/writing-modular-js/ (specifically “ES Harmony” section) discusses where TC39 are going in regards to implementing modules in ES.next.
So AMD and CommonJS can be used on server side or client side. In some cases one will work better for you than the other. You’ll need to do your homework as to what to use in which scenarios. Both have advantages and disadvantages that may work for or against you.
I’m keen to get a discussion going here on peoples experiences with the three MV* offerings mentioned. Especially those that have experience with two or more.